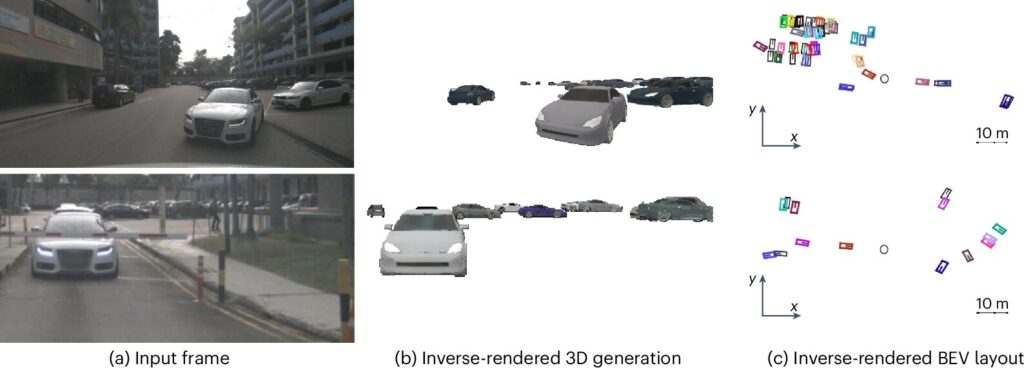
Researchers at Princeton University introduced a fresh way to reconstruct 3D scenes from 2D images. The method flips the usual image-analysis script by using inverse rendering. Instead of feeding images into a neural network and getting predictions, their system simulates how images are formed and adjusts a model to reproduce the input image—optimizing in reverse, reports Tech Xplore.
They use a differentiable rendering pipeline built on generative AI. The system begins with random 3D object models placed in a virtual scene. The generative model produces these based on hypothetical scene parameters. Then they render the scene into a 2D image and compare it with a real one. They measure discrepancy, backpropagate through both rendering and generation, and tweak inputs until the synthetic image aligns with the real one.
What this means is that the system effectively solves vision tasks as test-time optimization problems. You don’t train on new datasets for each scenario. The model generalizes across domains—without additional training—and delivers explicit 3D explanations of what it sees. That contrasts with opaque, feed-forward networks that struggle to adapt beyond their training set.
They tested this approach on multi-object tracking in autonomous driving datasets such as nuScenes and Waymo. The inverse rendering system performed on par with state-of-the-art learned models. But it also gave you interpretable 3D outputs—object positions, shapes, layouts—right out of the optimization.
This method cuts down on fine-tuning costs and could serve as an auto-labeling pipeline across different sets. The team aims to extend it to tasks like 3D detection and segmentation. Eventually, they want to reconstruct entire scenes, not just objects—letting robots build an evolving, explainable 3D model of their surroundings.