 The oceans contain an estimated 20 million tons of dissolved gold — roughly one gram per 100 million metric tons of seawater — but no cost-effective method of extracting it exists. (NOAA National Ocean Service)
The oceans contain an estimated 20 million tons of dissolved gold — roughly one gram per 100 million metric tons of seawater — but no cost-effective method of extracting it exists. (NOAA National Ocean Service)
The dream of a lights-out factory — one that operates autonomously without any humans in it, hence no need for light— is based on every machine having multiple sensors. These sensors provide data in various forms. Vision sensors, i.e., cameras (so we do need light, after all), provide data in video format. For example, a camera at a bottle-filling station could see if a bottle was not filled. A microphone sensor could provide data in audio format to detect abnormal sounds, such as a high-pitched whine that might signal bearing failure. A robot arm could be instrumented to provide positional data — 3D coordinates for each of its fingertips — as well as force feedback to prevent it from crushing the product.
The dream is that all the data streaming from all the sensors will create a virtual factory, the proverbial digital twin. The reality is, however, that the amount of data generated by sensors sensing 24/7 is overwhelming and if there is any valuable information, good luck finding it. Think of the particles of gold washed into the ocean.
Too Much of a Good Thing
It was only a few years ago that people were saying “data is the new oil.” It was wishful thinking. Crude oil has a relatively high yield when turned into fuel, chemicals, plastic, etc. Oil exists in limited supply. There’s an old saying about land that can be applied to oil: “They’re not making any more of it.” Data, on the other hand, is limitless. They’re making plenty of it. Enough to fill “data lakes,” a.k.a. server farms, though data oceans would be more appropriate.
A thoroughly instrumented factory can generate as much as 50 terabytes (TB) of data a day. One TB per day is not uncommon. Considering that War and Peace can be stored in one megabyte, a terabyte is one million War and Peaces. In 10 days, the 1-TB-a-day factory will fill the Library of Congress.
With so much of the buzz about AI focusing on its prodigious appetite for data centers, let’s not forget that data centers were first built for data. Memory for storage is still an ongoing need, taking up significant rack space in a data center.
Paying Attention
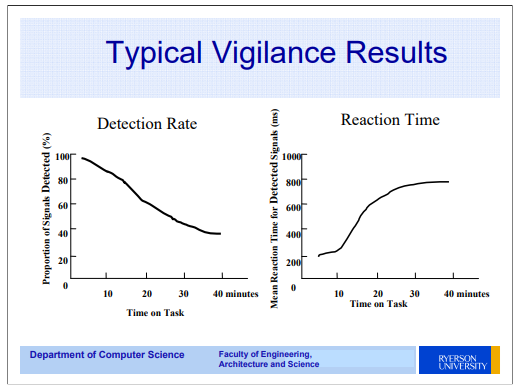
Finding enough gold in the ocean is not worthwhile for any human or machine. Same for finding significant items in data streams and lakes. Humans lose interest fast.
During World War II, the British military commissioned psychologist Norman Mackworth to study why radar operators near the end of their watch would miss enemy aircraft on their radar screens. His 1948 paper established what is now called the vigilance decrement: performance collapses within 20 to 35 minutes of monitoring a screen for rare events, with half the decline occurring in the first 15 minutes alone.
Enter AI
Into this ocean wades AI. Instead of a radar operator bored out of his gourd, we could have an AI agent with a voracious appetite for data. A well-trained AI agent would feast on data, including visual data from a camera feed. This AI agent doesn’t blink, much less fall asleep. It doesn’t take a bathroom break, much less take a vacation.
One company that makes agents for this purpose — and could potentially help filter the gold from the seawater — is HighByte. We talked to John Harrington, co-founder and chief product officer of HighByte on a Future of Design and Engineering Software podcast.
Industrial DataOps: The Missing Layer
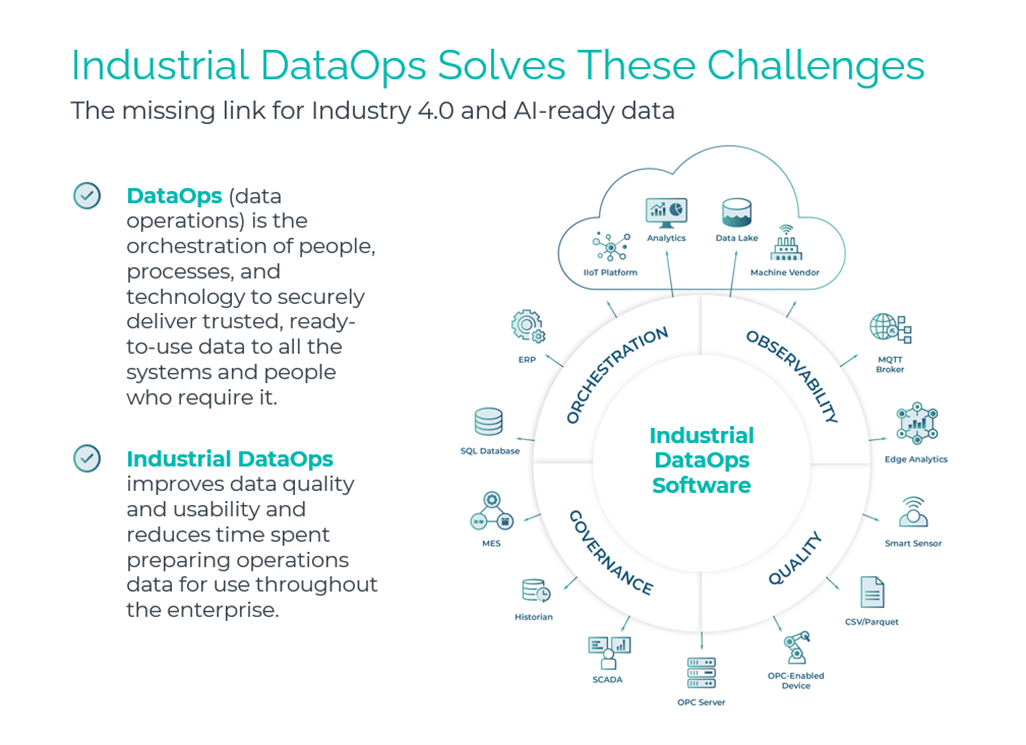
HighByte, founded in Portland, Maine, in 2018, is what Harrington calls an Industrial DataOps supplier. What is DataOps, you might ask. DataOps sits in a gap that many manufacturers don’t realize they have.
“Twenty years ago, the focus was how do I automate my factory floor,” Harrington says. “Today, what we’re realizing is if we could extract the data from that, there are a lot more business functions that could leverage it.” Quality teams, supply chain teams, design engineers — all of them, if given rich, contextualized knowledge of what’s happening on the shop floor, could do their jobs significantly better.
The problem is that raw factory data in its raw form isn’t something that can be dealt with. Data spews off machines in a stream of numbers with little attached meaning — like units. Is that data reading pressure or temperature? Which pump on which line? Without context, the numbers are just noise.
DataOps addresses that. Think of it as the next generation of data integration — not just moving data from Point A to Point B, but curating it for whoever needs to consume it. As Harrington puts it, the goal is to create a “data set that is knowledge.” A sensor reading without context is a data point. A sensor reading tagged with site, work cell, machine ID, state and timestamp is intelligence.
From Data Swamp to Data Pipeline
The IoT wave of the mid-2010s may have given the illusion that it solved the factory data problem. It largely didn’t. “IoT really hit its stride in 2015 and kind of started to die out in 2020,” Harrington observes. Two things went wrong: the data was hard to access in a usable form, and the platforms that emerged tended to solve only singular use cases — predictive maintenance, say, or quality monitoring — even as they sold themselves as universal solutions.
Companies that tried to deploy multiple IoT platforms found themselves managing overlapping, incompatible data flows. The alternative — dumping everything into a data lake without contextualization — produces “data swamps.” The data is all there. But without structure, it’s not usable and nobody wades in.
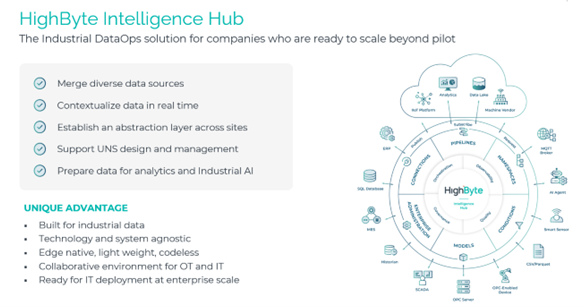
HighByte’s Intelligence Hub is designed to serve as the middle layer that IoT has never quite provided. It connects to both OT systems — the equipment, sensors and PLCs on the factory floor — and IT systems running in the cloud or on corporate networks. It pulls data from those sources, contextualizes it, standardizes it and routes it to wherever it needs to go: a cloud platform like AWS or Azure, an analytics dashboard, an MES or ERP system, or an AI agent.
HighByte does not analyze or visualize the data itself. It makes the data usable for whatever system is in place. That distinction matters. Rather than replacing existing enterprise software, it makes all of it work better by feeding it clean, contextualized inputs.
No-Code, No Programmers Required
The Intelligence Hub operates through a visual, drag-and-drop interface that is more like Visio than anything else. Engineers define data pipelines — what data to collect, how to transform it and where to send it — by dragging and dropping components into a visual workflow. No code needs to be written.
HighByte is not intended for a software engineer, but rather for an engineer who knows the systems, says Harrington.
“The data is structured and is able to just drag and drop and build up the data pipelines,” Harrington explains.
The system has AI built in. An engineer who hasn’t touched a pipeline in months can ask, in plain English, what the pipeline does or why it’s throwing errors. They can instruct it to add a processing stage. The AI explains, suggests and awaits approval — it doesn’t act unilaterally.
Harrington frames it as “AI for DataOps” — using AI to help humans configure and manage the data platform itself, distinct from using AI agents to monitor factory output.
Smart Filtering: Not Crude, but Curated
War is said to be long periods of boredom interrupted by sheer terror. Factory floor monitoring is similar: 99% of the data is unremarkable, boring even, and less than 1% demands immediate attention. So why ship all of it?
HighByte’s approach to filtering is focus: different consumers of data need it at different frequencies and granularities. A management dashboard might only need a reading every 10 minutes. A quality audit might require all data points collected during a specific production run. A motor health check might need one-millisecond resolution — but only in one-second bursts, sampled once an hour, not a continuous fire hose.
“The key is that for different use cases, different targets and different consumers of the data, you’re able to filter it differently,” Harrington says. The data isn’t discarded; it’s routed intelligently, so that each recipient gets exactly what they need in the form they need it.
Lindt Chocolates: An AI Agent on the Line

To see what this looks like in practice, consider one of HighByte’s more delicious customers: Lindt Chocolate. Lindt produces Lindor truffles in large trays — roughly 15-by-15 balls, more than a hundred chocolates per tray. For years, a human operator would visually inspect each tray as it moved down the line to spot defects. Every 15 seconds, a new tray. Minute after minute, hour after hour.
“Identifying small defects is very hard for a human, minute after minute, hour after hour, day after day,” Harrington says. “But it’s very easy for an AI.” A camera captures each tray; the image is sent to the cloud for analysis and the AI flags the defects. The human operator on the line — still very much present — responds to what the AI identifies. They don’t have to scan. They act.
Lindt uses HighByte both at its New Hampshire facility and across its European operations. “AI turns humans into superhuman,” Harrington says. The person is still there, still making the call — but with far better information, far faster, without the cognitive fatigue that makes human inspection unreliable over time.
The Agent Future
The Lindt example hints at a broader shift Harrington sees coming. Today, a factory’s data might feed 10 to 50 systems or users. In the near future, it could feed thousands of AI agents — one watching for maintenance issues on each machine, one monitoring quality at each work cell, one tracking raw material consumption at each station.
“AI agents are best when they’re really focused,” Harrington explains. A generalist agent watching an entire factory is like the bored security guard in front of 50 screens. A focused agent assigned to a specific task, such as detecting an intruder, instead is the guard who only has to watch every screen and never needs a bathroom break.
The implication for industrial data infrastructure is significant. Multiply the number of consumers of factory data by a factor of 100 and the data management problem doesn’t just grow — it transforms. Without a system capable of organizing, contextualizing and routing that data to hundreds of specialized recipients, the agents have nothing useful to work with.
The gold stays in the ocean.
This is precisely the scenario HighByte is building for. With customers in 24 countries — including two who have deployed the Intelligence Hub across more than 100 factory sites each — the company has learned that scale is as hard as connectivity. Getting data to flow is the first problem. Governing it, maintaining it and keeping it consistent across dozens of global facilities is the harder one.
Finding the Signal in the Noise
 There’s a cartoon that Harrington would recognize: a salesman presenting a round wheel to a group of people who are dragging a cart with square wheels. They are too busy to invest. New technology often faces that problem. The factories that could most benefit from Industrial DataOps are often the ones that are too consumed with keeping the line running to evaluate new platforms.
There’s a cartoon that Harrington would recognize: a salesman presenting a round wheel to a group of people who are dragging a cart with square wheels. They are too busy to invest. New technology often faces that problem. The factories that could most benefit from Industrial DataOps are often the ones that are too consumed with keeping the line running to evaluate new platforms.
“Every person in a company has what’s really important to them right now,” Harrington acknowledges. HighByte’s target is the person whose burning question is how to become more efficient, how to reduce defects and how to leverage data to improve uptime. Those are the people ready to have the conversation.
For those people, the value proposition is straightforward: a quality engineer with access to real-time, contextualized factory data is not the same as a quality engineer flying blind. A design engineer who can see exactly where defects are being introduced in manufacturing can design them out. A maintenance team that gets an alert when a motor’s power signature begins to degrade — before it fails — can schedule repair during planned downtime rather than scrambling after an unplanned shutdown.
The factory data ocean is real and it’s not getting smaller. What’s changing is the ability to navigate it — to send in focused agents who know what they’re looking for, to route data to the people and systems that can act on it, and to do so at a scale that no human team could manage alone.