Deep learning-based human pose estimation, once limited to detecting 2D joints with methods such as OpenPose, Mediapipe, and YOLOPose, is now pushing into the more complex realm of 3D multi-person pose estimation. However, this transition remains fraught with difficulties, particularly when leveraging multiple camera views to reconstruct (x, y, z) joint positions in global space, reports Tech Xplore.
Early multi-stage pipelines—where each camera independently estimates 2D keypoints before matching them across views and triangulating 3D positions—suffer from cascading errors. The initial step discards raw pixel data, limiting downstream accuracy, and any misstep in the chain compounds, undermining final pose estimation.
End-to-end learning models attempt to streamline this by processing all multi-view inputs together and directly regressing 3D joint positions. Innovations such as Learnable Triangulation, MvP (which uses geometric attention to fuse multi-view data), and MVGFormer (which tackles overfitting) have emerged—but each comes with its own shortcomings.
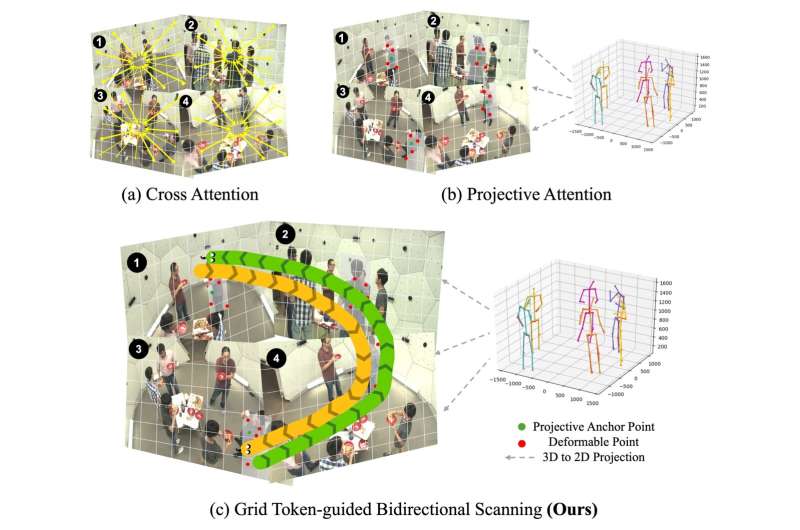
A notable breakthrough is the newly proposed MV-SSM model, introduced at CVPR 2025. It employs Projective State Space (PSS) blocks and a Grid Token-guided Bidirectional Scanning (GTBS) mechanism to more effectively model spatial relationships at the feature and keypoint levels. MV-SSM significantly improves generalization across varying camera setups—leading by margins of +24% in three-camera, +13% in rearranged-camera, and +38% in cross-dataset evaluations.
Yet, a critical limitation persists: all current models—including MV-SSM—still assume known camera calibration parameters. Real-world applications often require flexibility in camera count, arrangement, and environmental context—making this assumption a key barrier to broader deployment.