Artificial intelligence systems are growing larger, costlier, and more energy-intensive, prompting researchers to rethink how machine-learning hardware processes information. An IEEE Spectrum article examines a promising alternative known as sparse computing, which focuses on skipping unnecessary calculations rather than processing every data point equally. The approach could significantly improve the efficiency of large AI models while reducing infrastructure demands.
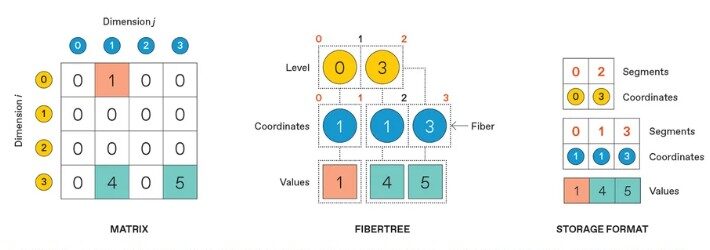
Traditional AI accelerators, including GPUs, typically perform dense computations in which every mathematical operation is executed, even when many values are effectively zero and contribute little to the final result. Sparse AI leverages this imbalance by identifying and ignoring insignificant values. Researchers estimate that many neural-network operations contain large numbers of zeros, meaning much of the computation performed by conventional hardware is wasted.
The article highlights work on specialized sparse accelerators such as the Onyx architecture, designed to process only meaningful data while bypassing redundant calculations. By exploiting sparsity directly in hardware, these systems can deliver faster processing speeds and lower energy consumption. The challenge lies in managing irregular data structures efficiently, since sparse information is more difficult to organize and move through memory than dense matrices.
Researchers are also exploring ways to combine sparse and dense processing on the same chip, enabling rapid transitions between computation styles depending on the workload. Another major area of development involves improving memory management and distributing sparse computations across multiple accelerator chips. These advances could help AI systems scale without requiring ever-expanding power supplies and cooling infrastructure.
The article argues that sparse computing may become increasingly important as AI models continue to expand in size and complexity. Beyond improving performance, the technology could address growing concerns about the environmental cost of training and operating large language models. Researchers see sparse architectures not merely as an optimization technique, but as a potential foundation for a more sustainable generation of AI systems.