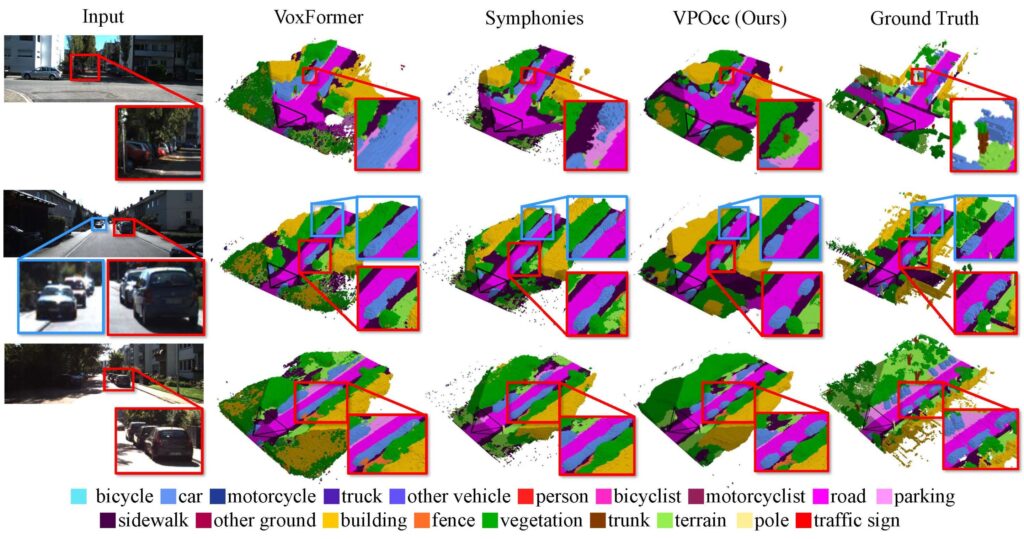
Researchers at the Ulsan National Institute of Science and Technology (UNIST), led by Kyungdon Joo, have developed an AI framework named VPOcc that harnesses the geometric principle of the vanishing point, used by Renaissance artists to depict depth on a flat canvas, to improve camera-only perception in autonomous vehicles, tells Tech Xplore.
Cameras are cheaper, lighter, and more flexible than LIDAR sensors for autonomous vehicles and robots, but they suffer from perspective distortion: objects farther away appear smaller and may be misperceived, causing gaps in 3D scene understanding. To address this, VPOcc uses three modules:
- VPZoomer, which warps the image using the vanishing-point homography to correct perspective distortion at the pixel level.
- VP-guided cross-attention (VPCA), which aggregates features from near and far regions with perspective awareness to balance information.
- Spatial Volume Fusion (SVF), merges the original image features and the corrected ones to complement their strengths and eliminate weaknesses.
In benchmark tests (such as SemanticKITTI and SSCBench-KITTI360), VPOcc outperformed existing models in mean Intersection over Union (mIoU) and scene reconstruction accuracy (IoU), especially in detecting distant objects and distinguishing overlapping entities, key for safe autonomous driving in complex environments.
The approach demonstrates how borrowing a centuries-old artistic concept can solve a modern engineering problem: translating 2D camera data into accurate 3D spatial understanding. The researchers expect VPOcc to find uses beyond driving, i.e., in robotics, augmented reality mapping, and other perception systems.
By enabling camera-centric systems to better infer depth and occupancy, this research offers a more cost-effective and efficient alternative to heavy reliance on LIDAR, helping accelerate autonomous system deployment in real-world scenarios.